JVM探索-2.G1垃圾回收器基础概念
时间:2022-10-27 23:16 作者:林立 分类: 作品
通常我们所说的GC是指垃圾回收,但是在JVM的实现中GC更为准确的意思是指内存管理器,它有两个职能,第一是内存的分配管理,第二是垃圾回收。这两者是一个事物的两个方面,每一种垃圾回收策略都和内存的分配策略息息相关,脱离内存的分配去谈垃圾回收是没有任何意义的。
分区
分区(Heap Region,HR)或称堆分区,是G1堆和操作系统交互的最小管理单位。G1的分区类型(HeapRegionType)大致可以分为四类:
- 自由分区(Free Heap Region,FHR)
- 新生代分区(Young Heap Region,YHR)
- 大对象分区(Humongous Heap Region,HHR)
- 老生代分区(Old Heap Region,OHR)
其中新生代分区又可以分为Eden和Survivor;大对象分区又可以分为:大对象头分区和大对象连续分区。
每一个分区都对应一个分区类型,在代码中常见的is_young、is_old、is_houmongous等判断分区类型的函数都是基于上述的分区类型实现,关于分区类型代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/heapRegionType.hpp
// 0000 0 [ 0] Free
//
// 0001 0 Young Mask
// 0001 0 [ 2] Eden
// 0001 1 [ 3] Survivor
//
// 0010 0 Humongous Mask
// 0010 0 [ 4] Humongous Starts
// 0010 1 [ 5] Humongous Continues
//
// 01000 [ 8] Old 在G1中每个分区的大小都是相同的。该如何设置HR的大小?设置HR的大小有哪些考虑?
在G1中每个分区的大小都是相同的。该如何设置HR的大小?设置HR的大小有哪些考虑?
HR的大小直接影响分配和垃圾回收效率。如果过大,一个HR可以存放多个对象,分配效率高,但是回收的时候花费时间过长;如果太小则导致分配效率低下。为了达到分配效率和清理效率的平衡,HR有一个上限值和下限值,目前上限是32MB,下限是1MB(为了适应更小的内存分配,下限可能会被修改,在目前的版本中HR的大小只能为1MB、2MB、4MB、8MB、16MB和32MB),默认情况下,整个堆空间分为2048个HR(该值可以自动根据最小的堆分区大小计算得出)。HR大小可由以下方式确定:
- 可以通过参数G1HeapRegionSize来指定大小,这个参数的默认值为0。
- 启发式推断,即在不指定HR大小的时候,由G1启发式地推断HR大小。
HR启发式推断根据堆空间的最大值和最小值以及HR个数进行推断,设置Initial HeapSize(默认为0)等价于设置Xms,设置MaxHeapSize(默认为96MB)等价于设置Xmx。堆分区默认大小的计算方式在HeapRegion.cpp中的setup_heap_region_size(),-代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/heapRegion.cpp
void HeapRegion::setup_heap_region_size(...) {
/*判断是否是设置过堆分区大小,如果有则使用;没有,则根据初始内存和最大分配内存,获得平均值,并根据HR的个数得到分区的大小,和分区的下限比较,取两者的最大值。*/
uintx region_size = G1HeapRegionSize;
if (FLAG_IS_DEFAULT(G1HeapRegionSize)) {
size_t average_heap_size = (initial_heap_size + max_heap_size) / 2;
region_size = MAX2(average_heap_size / HeapRegionBounds::target_number(),
(uintx) HeapRegionBounds::min_size());
}
// 对region_size按2的幂次对齐,并且保证其落在上下限范围内
int region_size_log = log2_long((jlong) region_size);
region_size = ((uintx)1 << region_size_log);
// 确保region_size落在[1MB,32MB]之间
if (region_size < HeapRegionBounds::min_size()) {
region_size = HeapRegionBounds::min_size();
} else if (region_size > HeapRegionBounds::max_size()) {
region_size = HeapRegionBounds::max_size();
}
// 根据region_size计算一些变量,如卡表大小
region_size_log = log2_long((jlong) region_size);
LogOfHRGrainBytes = region_size_log;
LogOfHRGrainWords = LogOfHRGrainBytes - LogHeapWordSize;
GrainBytes = (size_t)region_size;
GrainWords = GrainBytes >> LogHeapWordSize;
CardsPerRegion = GrainBytes >> CardTableModRefBS::card_shift; 按照默认值计算,G1可以管理的最大内存为2048×32MB=64GB。假设设置xms=32G,xmx=128G,则每个堆分区的大小为32M,分区个数动态变化范围从1024到4096个。
G1中大对象不使用新生代空间,直接进入老生代,那么多大的对象能称为大对象?简单来说是region_size的一半。
新生代大小
新生代大小指的是新生代内存空间的大小,前面提到G1中新生代大小按分区组织,即首先计算整个新生代的大小,然后根据上一节中的计算方法计算得到分区大小,两者相除得到需要多少个分区。G1中与新生代大小相关的参数设置和其他GC算法类似,G1中还增加了两个参数G1MaxNewSizePercent和G1NewSizePercent用于控制新生代的大小,整体逻辑如下:
- 如果设置新生代最大值(MaxNewSize)和最小值(NewSize),可以根据这些值计算新生代包含的最大的分区和最小的分区;注意Xmn等价于设置了MaxNewSize和NewSize,且NewSize=MaxNewSize。
- 如果既设置了最大值或者最小值,又设置了NewRatio,则忽略NewRatio。
- 如果没有设置新生代最大值和最小值,但是设置了NewRatio,则新生代的最大值和最小值是相同的,都是整个堆空间/(NewRatio+1)。
- 如果没有设置新生代最大值和最小值,或者只设置了最大值和最小值中的一个,那么G1将根据参数G1MaxNewSizePercent(默认值为60)和G1NewSizePercent(默认值为5)占整个堆空间的比例来计算最大值和最小值。
如果G1推断出最大值和最小值相等,则说明新生代不会动态变化。不会动态变化意味着G1在后续对新生代垃圾回收的时候可能不能满足期望停顿的时间。
新生代大小相关的代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1CollectorPolicy.cpp
// 初始化新生代大小参数,根据不同的JVM参数判断计算新生代大小,供后续使用
G1YoungGenSizer::G1YoungGenSizer() : _sizer_kind(SizerDefaults), _adaptive_
size(true), _min_desired_young_length(0), _max_desired_young_length(0) {
// 如果设置NewRatio且同时设置NewSize或MaxNewSize的情况下,则NewRatio被忽略
if (FLAG_IS_CMDLINE(NewRatio)) {
if (FLAG_IS_CMDLINE(NewSize) || FLAG_IS_CMDLINE(MaxNewSize)) {
warning("-XX:NewSize and -XX:MaxNewSize override -XX:NewRatio");
} else {
_sizer_kind = SizerNewRatio;
_adaptive_size = false;
return;
}
}
// 参数传递有问题,最小值大于最大值
if (NewSize > MaxNewSize) {
if (FLAG_IS_CMDLINE(MaxNewSize)) {
warning("…”);
}
MaxNewSize = NewSize;
}
// 根据参数计算分区的个数
if (FLAG_IS_CMDLINE(NewSize)) {
_min_desired_young_length = MAX2((uint) (NewSize / HeapRegion::
GrainBytes), 1U);
if (FLAG_IS_CMDLINE(MaxNewSize)) {
_max_desired_young_length = MAX2((uint) (MaxNewSize / HeapRegion::
GrainBytes), 1U);
_sizer_kind = SizerMaxAndNewSize;
_adaptive_size = _min_desired_young_length == _max_desired_young_length;
} else {
_sizer_kind = SizerNewSizeOnly;
}
} else if (FLAG_IS_CMDLINE(MaxNewSize)) {
_max_desired_young_length = MAX2((uint) (MaxNewSize / HeapRegion::
GrainBytes), 1U);
_sizer_kind = SizerMaxNewSizeOnly;
}
}
// 使用G1NewSizePercent来计算新生代的最小值
uint G1YoungGenSizer::calculate_default_min_length(uint new_number_of_heap_
regions) {
uint default_value = (new_number_of_heap_regions * G1NewSizePercent) / 100;
return MAX2(1U, default_value);
}
// 使用G1MaxNewSizePercent来计算新生代的最大值
uint G1YoungGenSizer::calculate_default_max_length(uint new_number_of_heap_
regions) {
uint default_value = (new_number_of_heap_regions * G1MaxNewSizePercent) / 100;
return MAX2(1U, default_value);
}
/*这里根据不同的参数输入来计算大小。recalculate_min_max_young_length在初始化时被调用,在堆空间改变时也会被调用。*/
void G1YoungGenSizer::recalculate_min_max_young_length(uint number_of_heap_
regions, uint* min_young_length, uint* max_young_length) {
assert(number_of_heap_regions > 0, "Heap must be initialized");
switch (_sizer_kind) {
case SizerDefaults:
*min_young_length = calculate_default_min_length(number_of_heap_regions);
*max_young_length = calculate_default_max_length(number_of_heap_regions);
break;
case SizerNewSizeOnly:
*max_young_length = calculate_default_max_length(number_of_heap_regions);
*max_young_length = MAX2(*min_young_length, *max_young_length);
break;
case SizerMaxNewSizeOnly:
*min_young_length = calculate_default_min_length(number_of_heap_regions);
*min_young_length = MIN2(*min_young_length, *max_young_length);
break;
case SizerMaxAndNewSize:
// Do nothing. Values set on the command line, don't update them at runtime.
break;
case SizerNewRatio:
*min_young_length = number_of_heap_regions / (NewRatio + 1);
*max_young_length = *min_young_length;
break;
default:
ShouldNotReachHere();
}
}如果G1是启发式推断新生代的大小,那么当新生代变化时该如何实现?简单地说,使用一个分区列表,扩张时如果有空闲的分区列表则可以直接把空闲分区加入到新生代分区列表中,如果没有的话则分配新的分区然后把它加入到新生代分区列表中。G1有一个线程专门抽样处理预测新生代列表的长度应该多大,并动态调整。
另外还有一个问题,就是分配新的分区时,何时扩展?一次扩展多少内存?
G1是自适应扩展内存空间的。参数 -XX:GCTimeRatio 表示GC与应用的耗费时间比,G1中默认为9,计算方式为_gc_overhead_perc=100.0×(1.0/(1.0+GCTimeRatio)),即G1 GC时间与应用时间占比不超过10%时不需要动态扩展,当GC时间超过这个阈值的10%,可以动态扩展。扩展时有一个参数G1ExpandByPercentOfAvailable(默认值是20)来控制一次扩展的比例,即每次都至少从未提交的内存中申请20%,有下限要求(一次申请的内存不能少于1M,最多是当前已分配的一倍),代码如下所示:
size_t G1CollectorPolicy::expansion_amount() {
// 先根据历史信息获取平均GC时间
double recent_gc_overhead = recent_avg_pause_time_ratio() * 100.0;
double threshold = _gc_overhead_perc;
/* G1 GC时间与应用时间占比超过阈值才需要动态扩展,这个阈值的值为_gc_overhead_perc = 100.0 × (1.0 / (1.0 + GCTimeRatio)),上文提到GCTimeRatio=9,即超过10%才会扩张内存*/
if (recent_gc_overhead > threshold) {
const size_t min_expand_bytes = 1*M;
size_t reserved_bytes = _g1->max_capacity();
size_t committed_bytes = _g1->capacity();
size_t uncommitted_bytes = reserved_bytes - committed_bytes;
size_t expand_bytes;
size_t expand_bytes_via_pct = uncommitted_bytes * G1ExpandByPercentOfAvailable / 100;
expand_bytes = MIN2(expand_bytes_via_pct, committed_bytes);
expand_bytes = MAX2(expand_bytes, min_expand_bytes);
expand_bytes = MIN2(expand_bytes, uncommitted_bytes);
……
return expand_bytes;
} else {
return 0;
}
}G1停顿预测模型
G1是一个响应时间优先的GC算法,用户可以设定整个GC过程的期望停顿时间,由参数MaxGCPauseMillis控制,默认值200ms。不过它不是硬性条件,只是期望值,G1会努力在这个目标停顿时间内完成垃圾回收的工作,但是它不能保证,即也可能完不成(比如我们设置了太小的停顿时间,新生代太大等)。
那么G1怎么满足用户的期望呢?就需要停顿预测模型了。G1根据这个模型统计计算出来的历史数据来预测本次收集需要选择的堆分区数量(即选择收集哪些内存空间),从而尽量满足用户设定的目标停顿时间。如使用过去10次垃圾回收的时间和回收空间的关系,根据目前垃圾回收的目标停顿时间来预测可以收集多少的内存空间。比如最简单的办法是使用算术平均值建立一个线性关系来预测。如过去10次一共收集了10GB的内存,花费了1s,那么在200ms的停顿时间要求下,最多可以收集2GB的内存空间。G1的预测逻辑是基于衰减平均值和衰减标准差。
衰减平均(Decaying Average)是一种简单的数学方法,用来计算一个数列的平均值,核心是给近期的数据更高的权重,即强调近期数据对结果的影响。衰减平均计算公式如下所示:
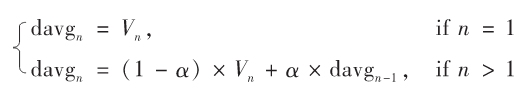
式中α为历史数据权值,1-α为最近一次数据权值。即α越小,最新的数据对结果影响越大,最近一次的数据对结果影响最大。不难看出,其实传统的平均就是α取值为(n-1)/n的情况。
同理,衰减方差的定义如下:
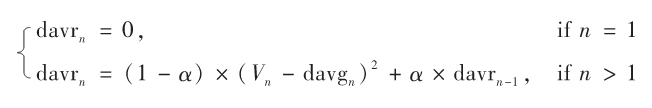
停顿预测模型是以衰减标准差为理论基础实现的,代码如下所示:
hotspot/src/share/vm/gc_implementation/g1/g1CollectorPolicy.hpp
double get_new_prediction(TruncatedSeq* seq) {
return MAX2(seq->davg() + sigma() * seq->dsd(),
seq->davg() * confidence_factor(seq->num()));
} 在这个预测计算公式中:
- davg表示衰减均值。
- sigma()返回一个系数,来自G1ConfidencePercent(默认值为50,sigma为0.5)的配置,表示信赖度。
- dsd表示衰减标准偏差。
- confidence_factor表示可信度相关系数,confidence_factor当样本数据不足时(小于5个)取一个大于1的值,并且样本数据越少该值越大。当样本数据大于5时confidence_factor取值为1。这是为了弥补样本数据不足,起到补偿作用。
- 方法的参数TruncateSeq,顾名思义,是一个截断的序列,它只跟踪序列中最新的n个元素。在G1 GC过程中,每个可测量的步骤花费的时间都会记录到TruncateSeq(继承了AbsSeq)中,用来计算衰减均值、衰减变量、衰减标准偏差等,代码如下所示:
hotspot/src/share/vm/utilities/numberSeq.cpp
void AbsSeq::add(double val) {
if (_num == 0) {
// 初始时,还没有历史数据,davg就是当前参数,dvar设置为0
_davg = val;
_dvariance = 0.0;
} else {
_davg = (1.0 - _alpha) * val + _alpha * _davg;
double diff = val - _davg;
_dvariance = (1.0 - _alpha) * diff * diff + _alpha * _dvariance;
}
}这个add方法就是上面两个衰减公式的实现代码。其中_davg为衰减均值,_dvariance为衰减方差,_alpha默认值为0.7。G1的软实时停顿就是通过这样的预测模型来实现的。